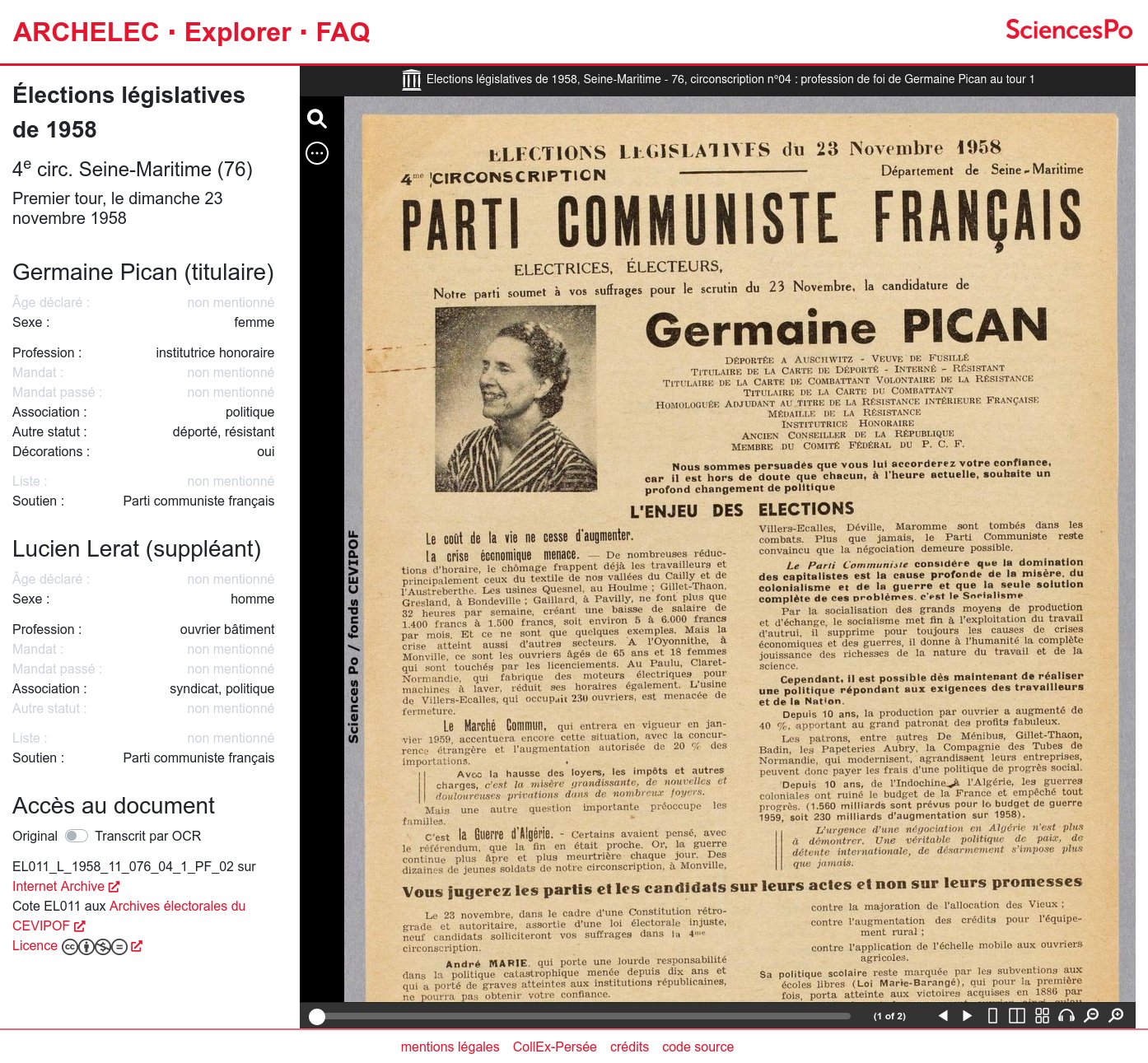
HOPPE-Droit
Explore a 19th-20th centuries French law educational works collection
The HOPPE-Droit projects aims to create and publish a collection of French law educational works from the 19th-20th centuries. We designed and developed an exploration tool which help studying the evolutions of the French law through education materials from the 19th century.
The dataset is edited by the CUJAS team in a Heurist database. These data are exported through API to be indexed into ElasticSearch. We made sure to keep data complexity by for instance taking care of dates incertainty and levels of precision. A web application finally allows to explore the dataset under different angles: books, authors, editors, co-publication networks, genealogies...
A Custom development project
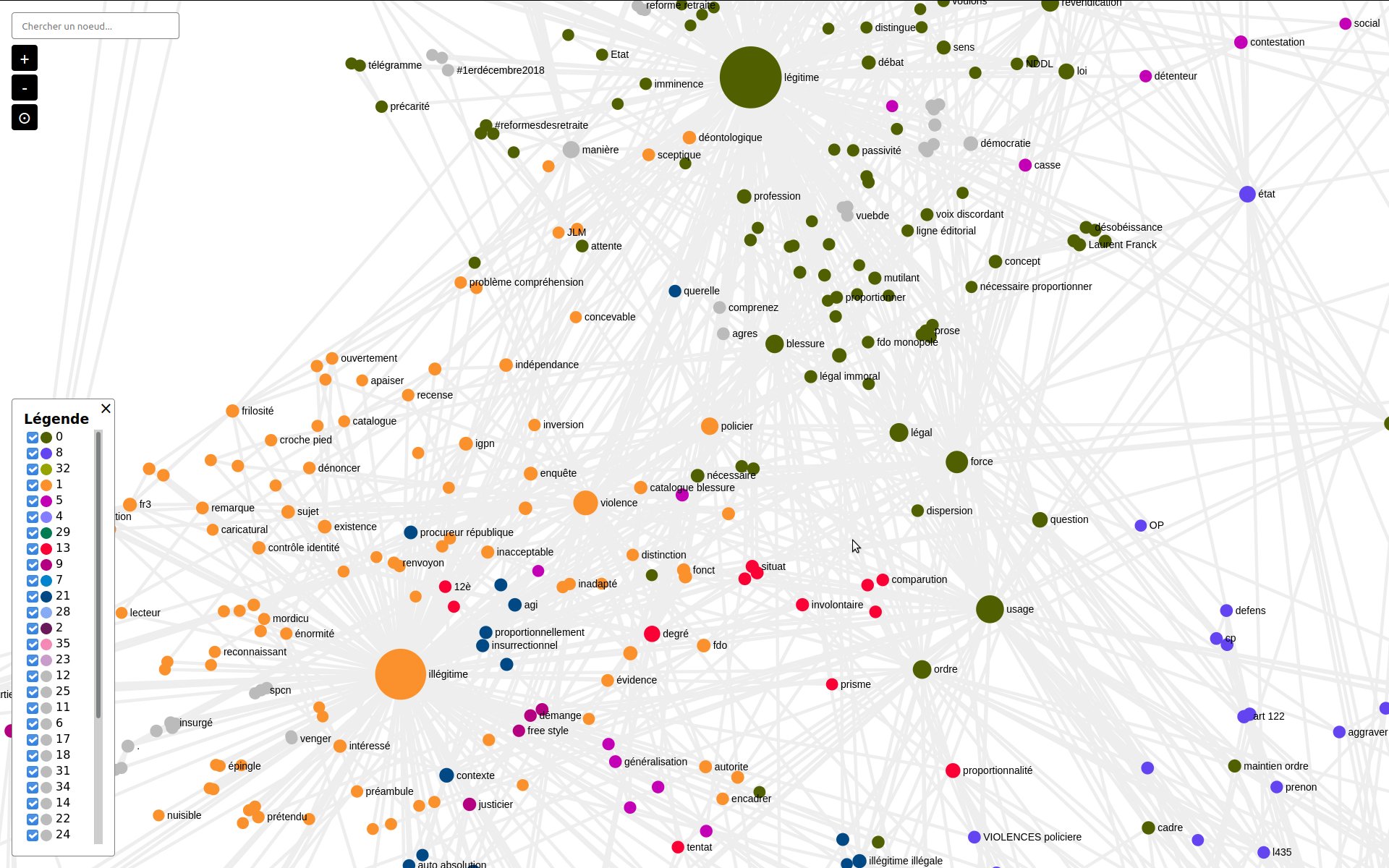
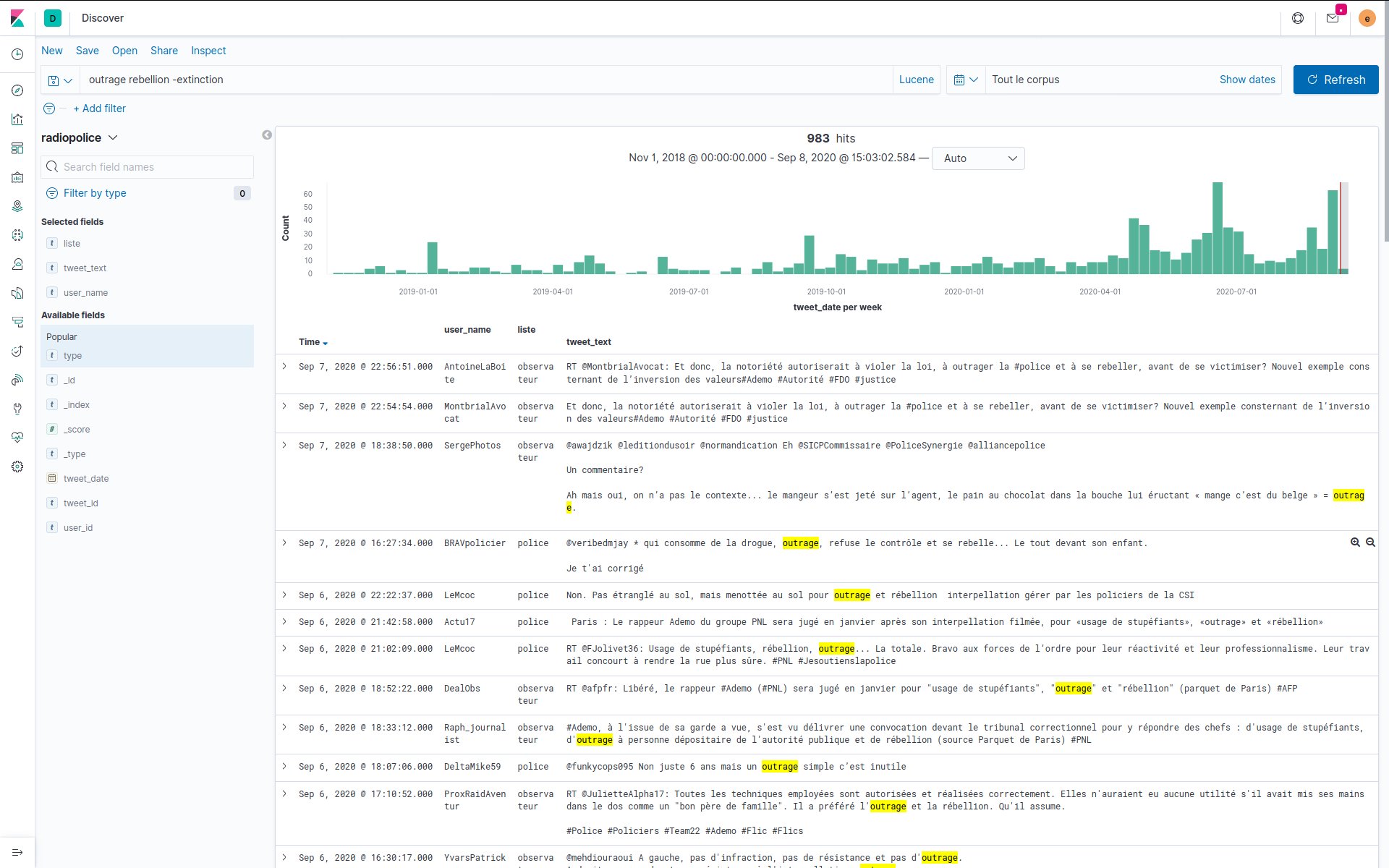
Faceted search on the collection authors
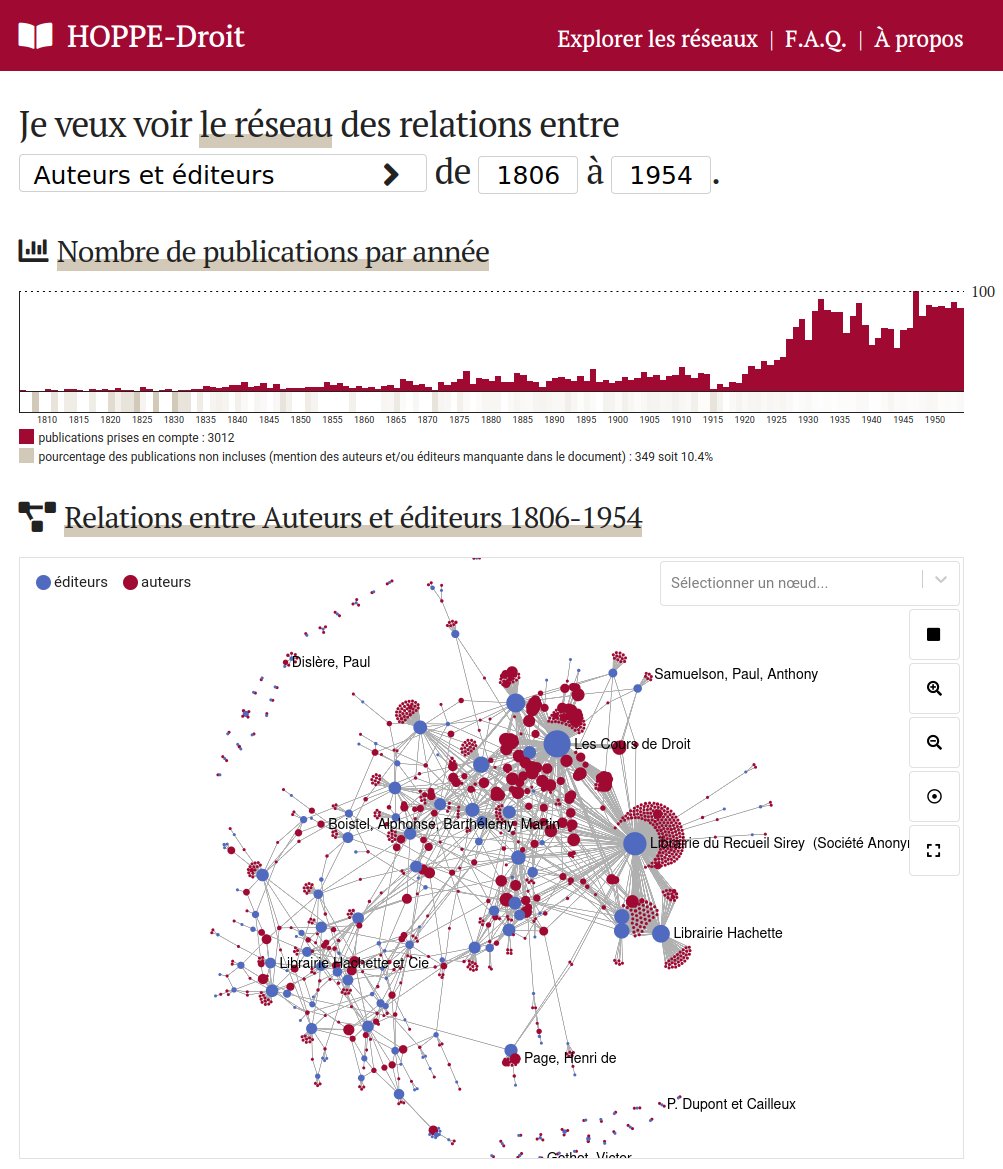
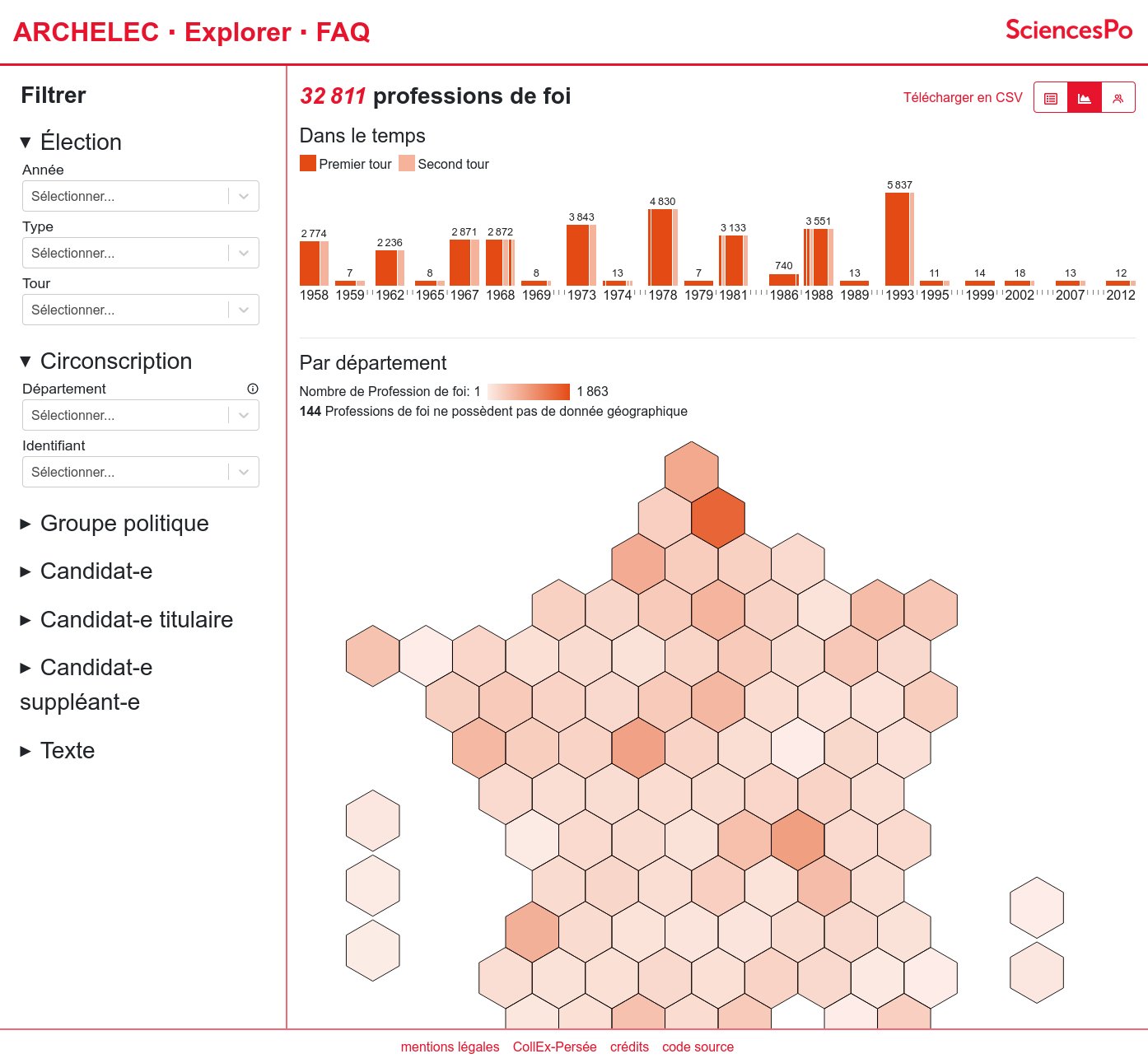
Network of authors-editors linked by educational works
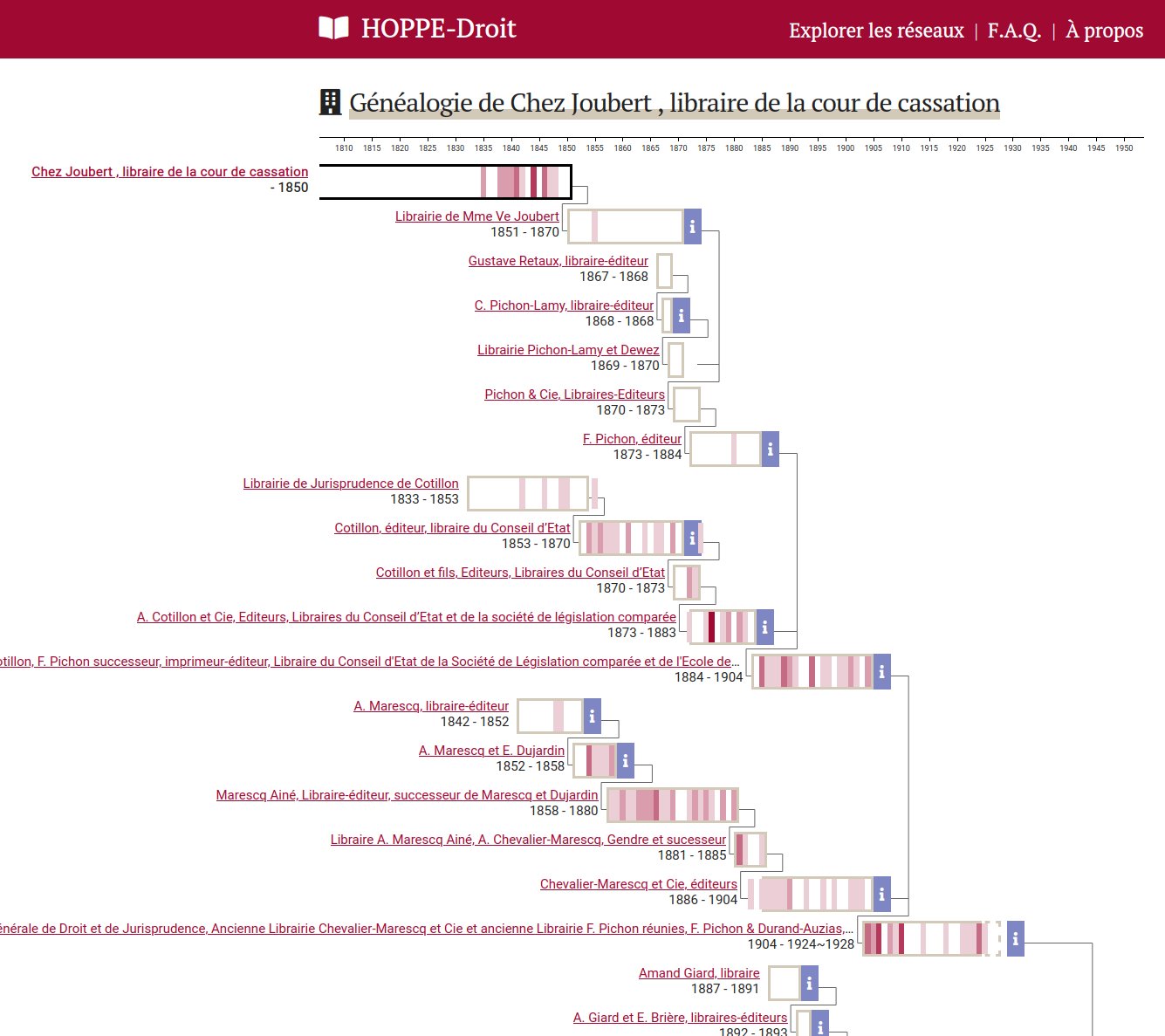
Editor's genealogy page summing up association, acquisition...