Hyphe
Indexation de contenu web et déploiement automatisé sur OpenStack
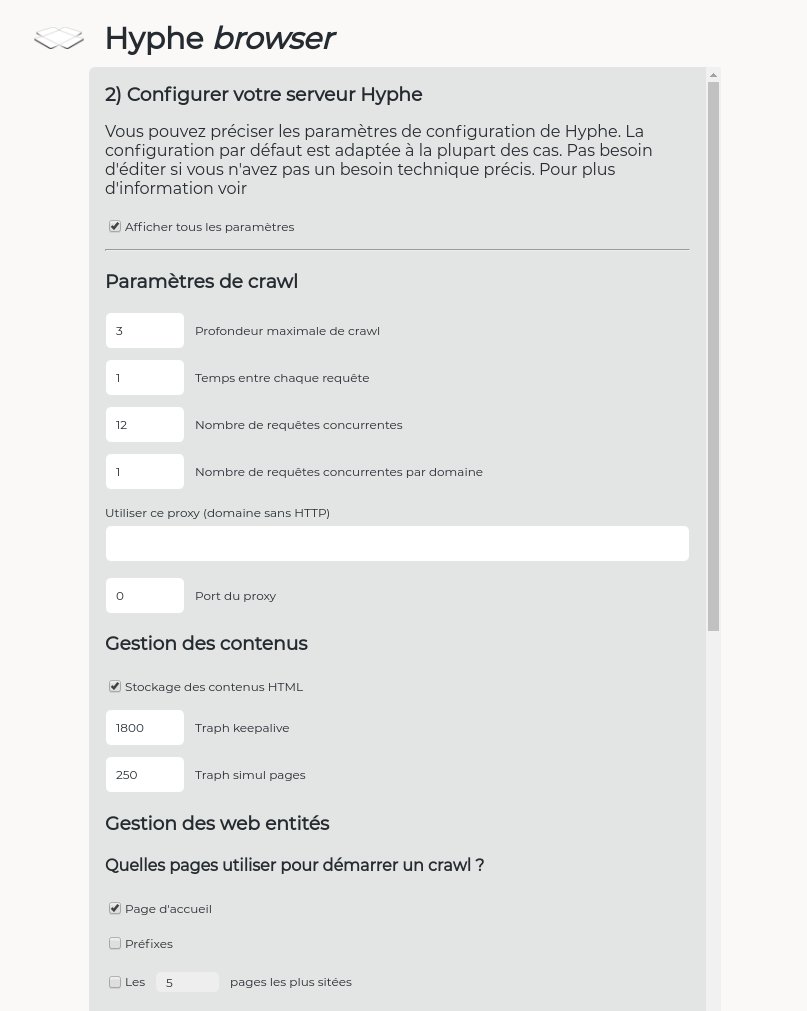
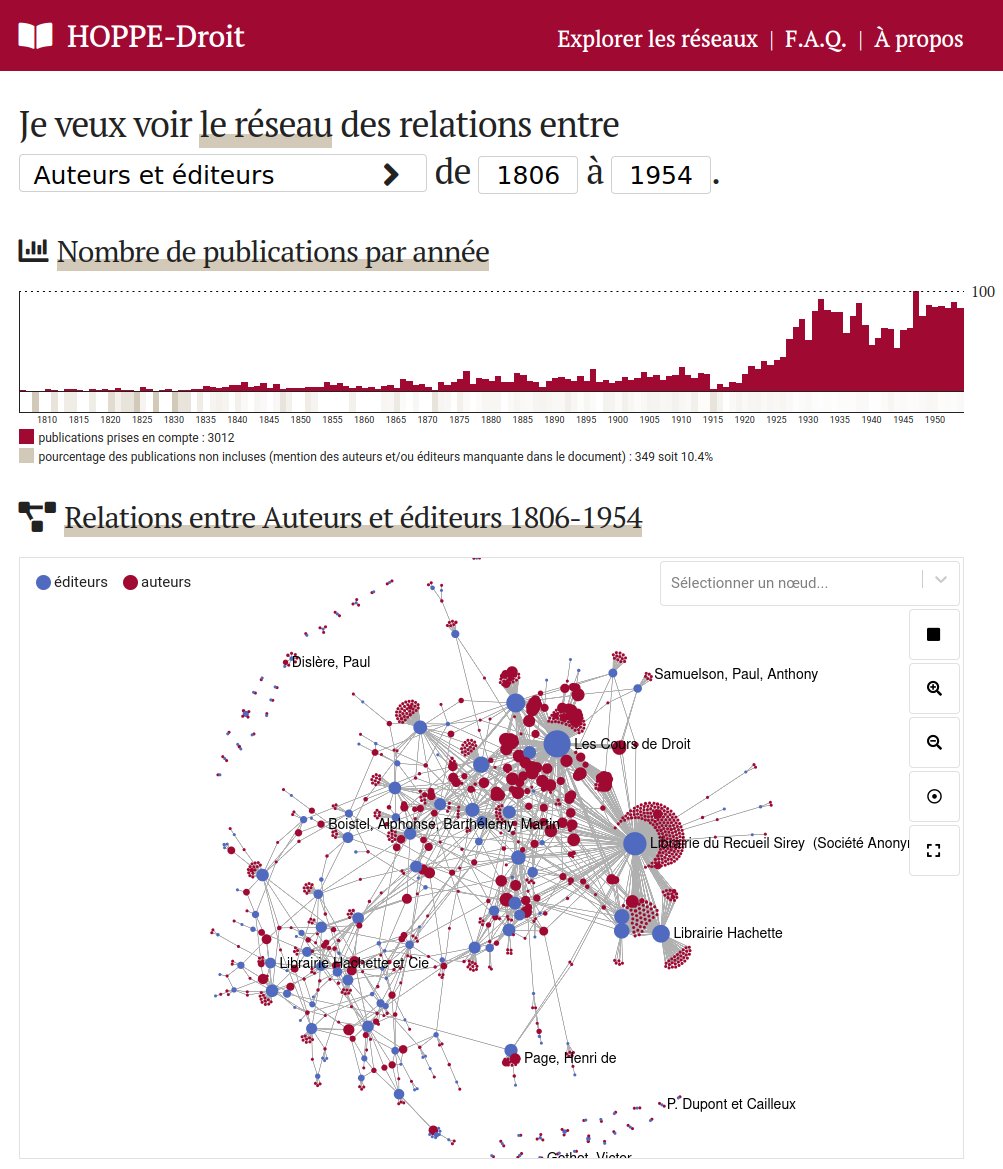
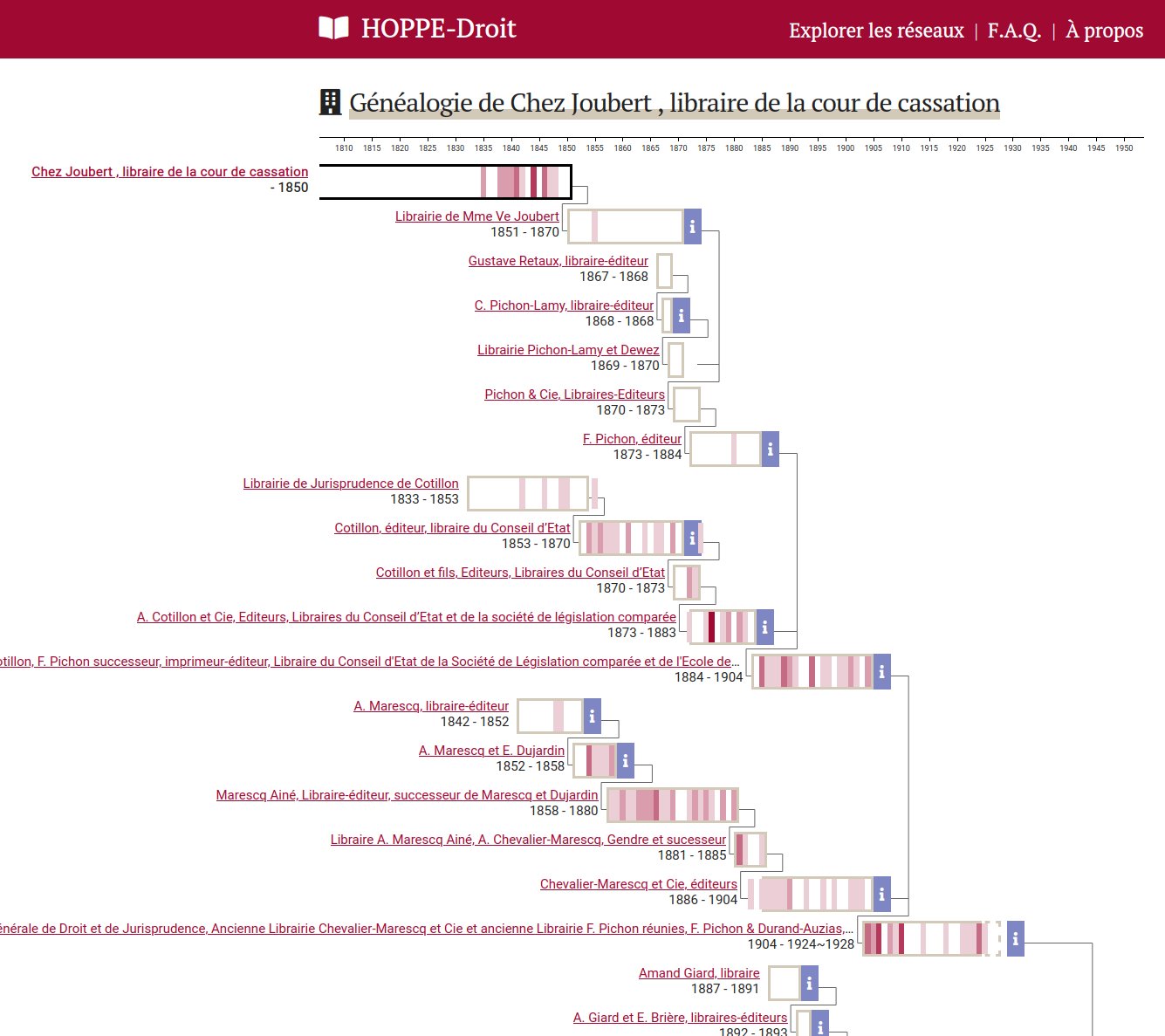
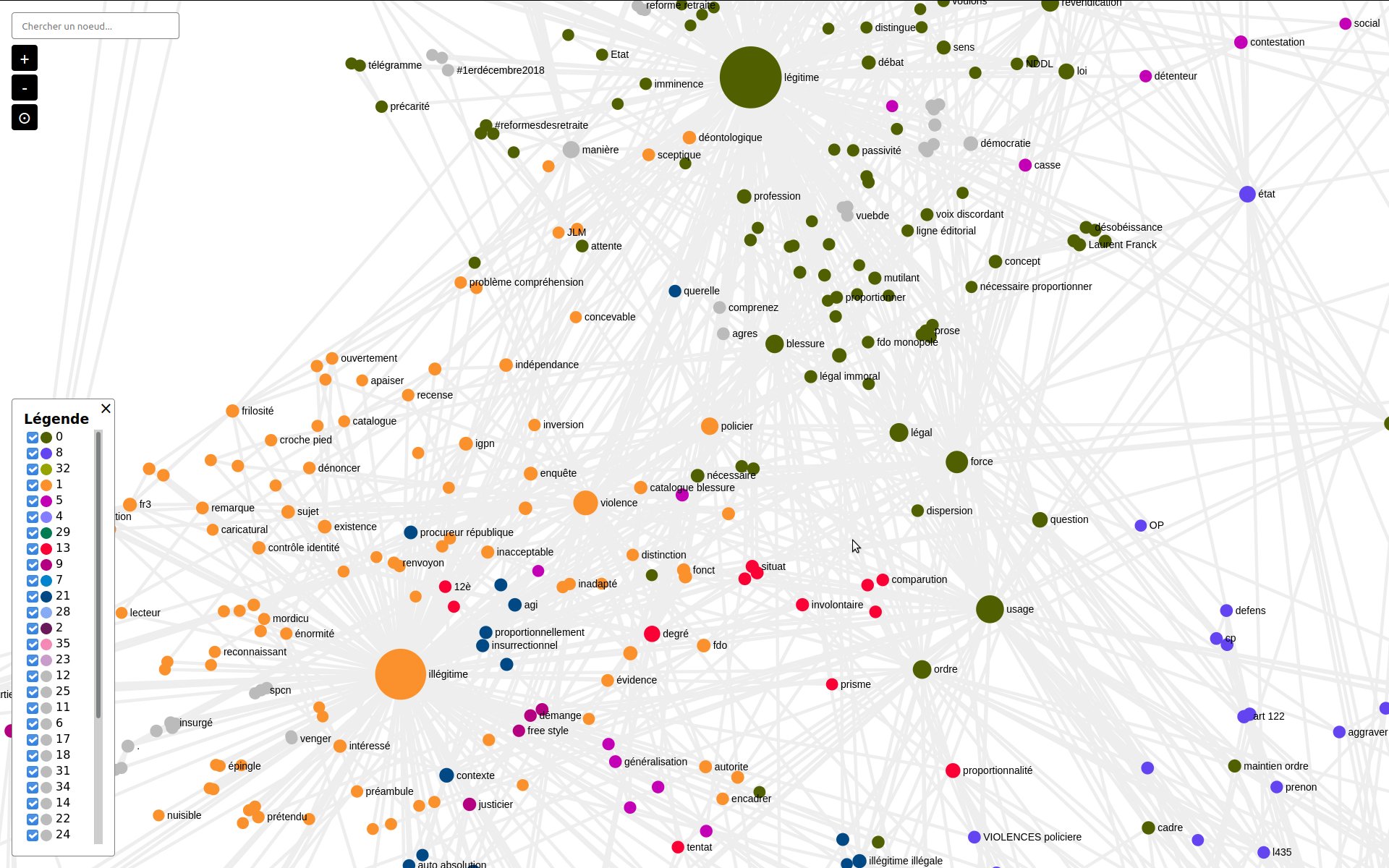
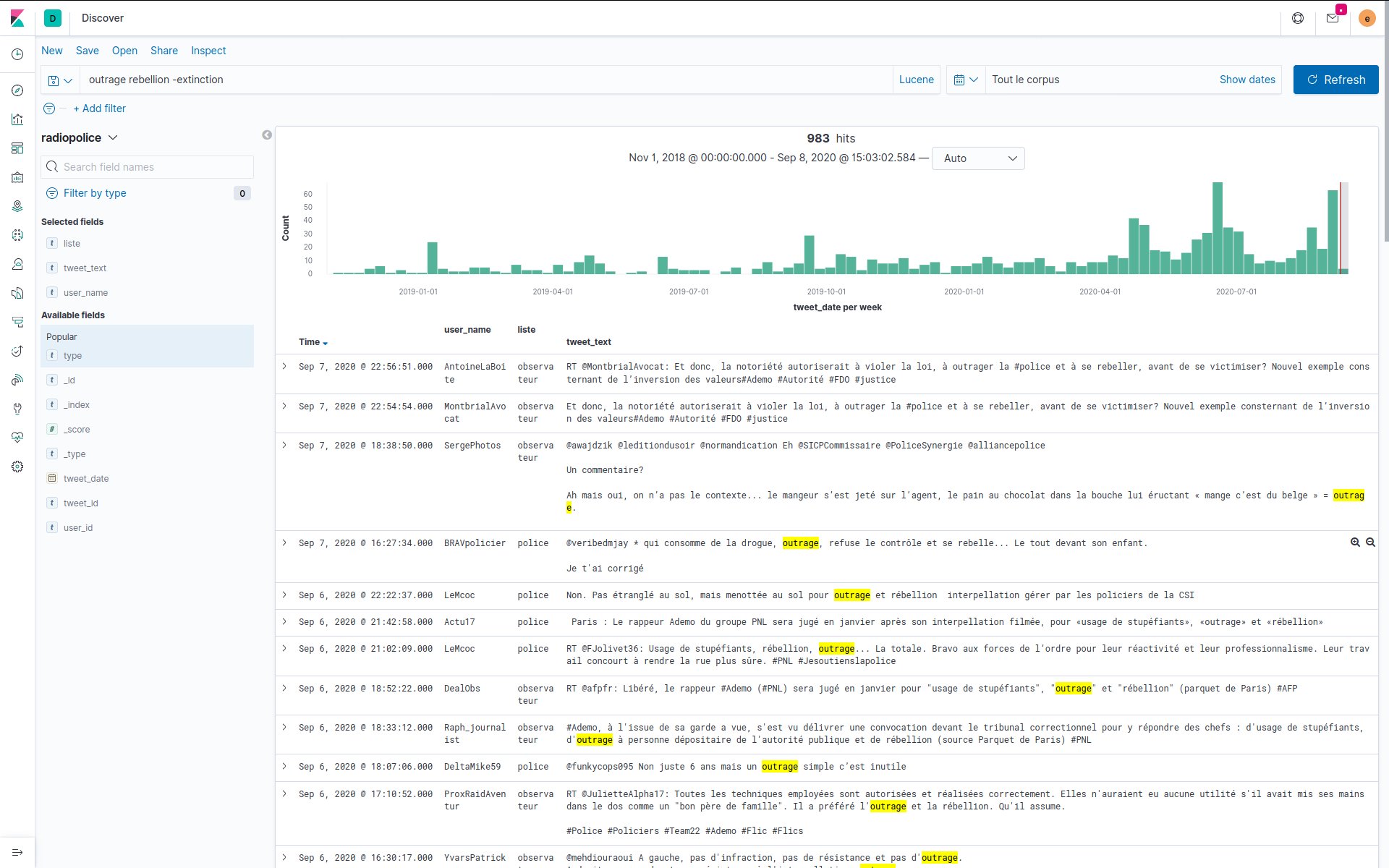
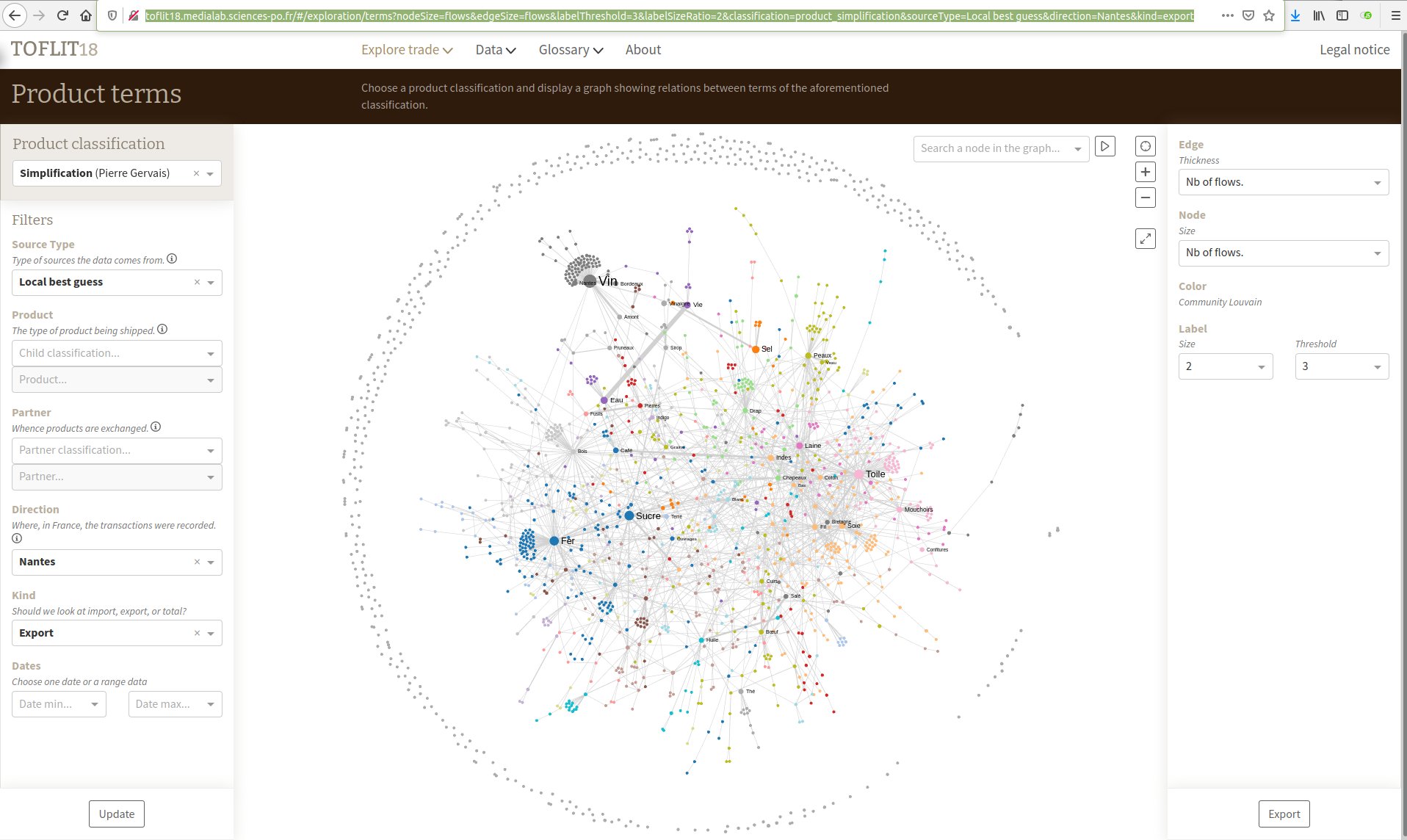
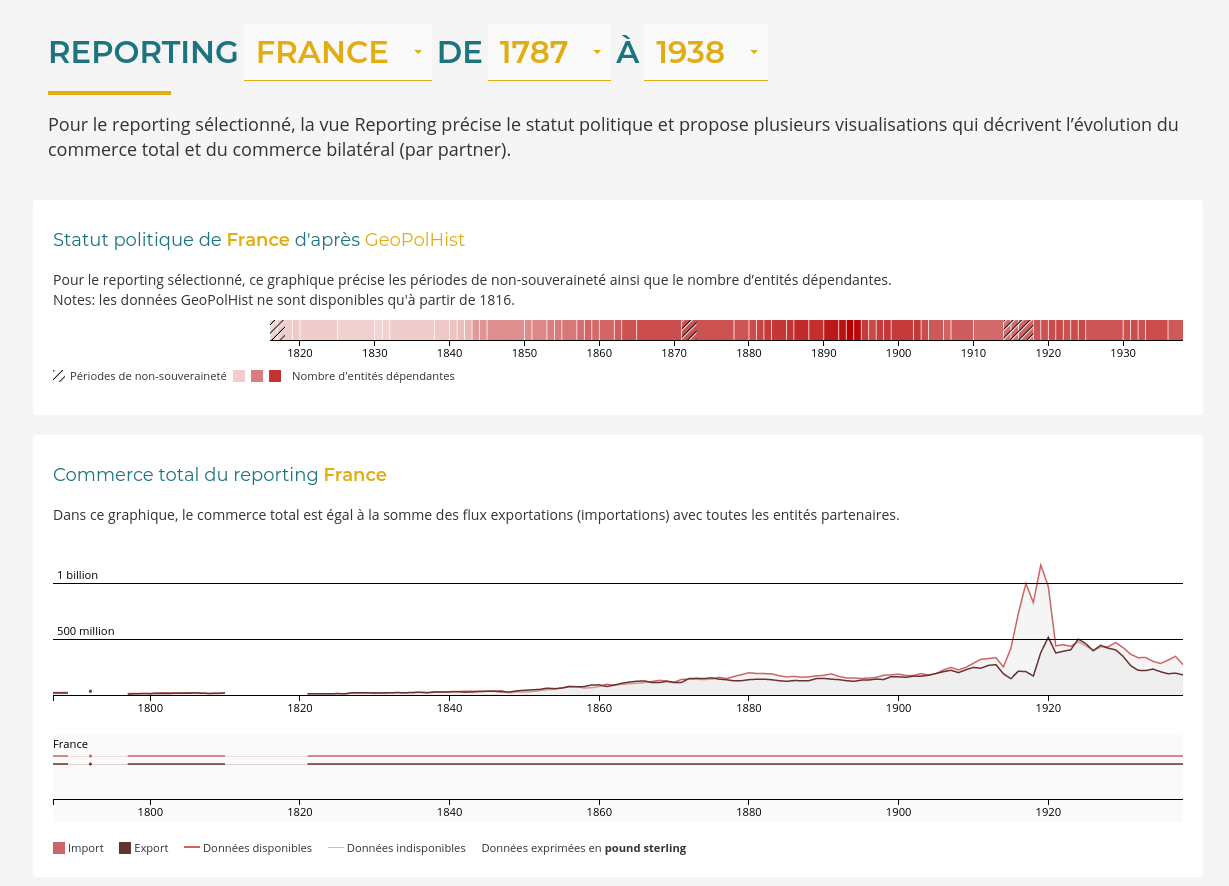
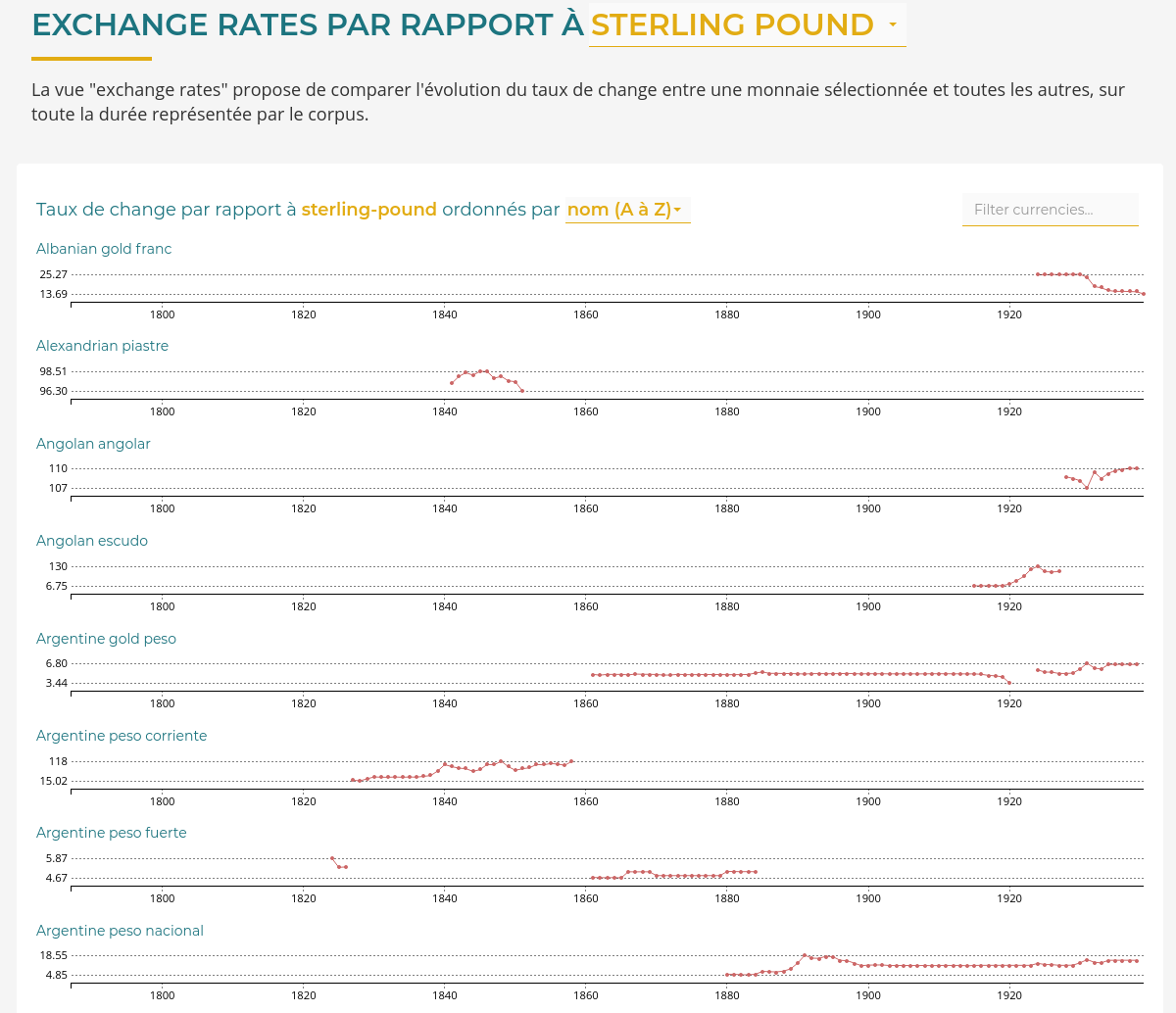
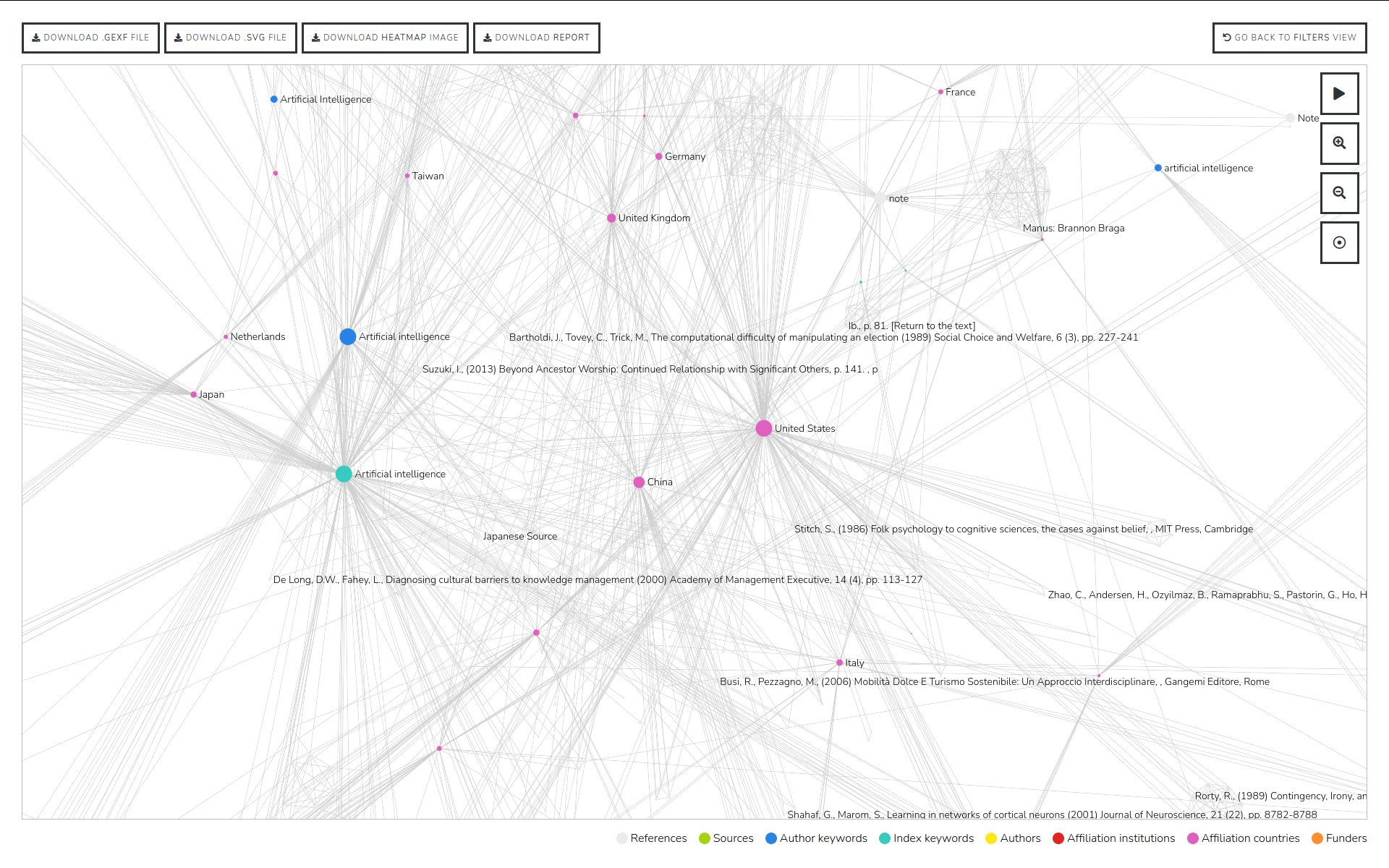
Hyphe est un crawler web conçu pour les chercheurs en sciences sociales, et développé par le médialab de Sciences-Po.
Nous y avons ajouté les fonctionnalités suivantes :
- Indexation textuelle automatique des corpus web par extraction puis indexation multiprocess des contenus dans ElasticSearch
- Déploiement automatique de serveurs Hyphe chez des hébergeurs compatibles OpenStack
Un projet de Code et Données ouvertes